New LLM Provider: Welcome Gemini!
We are excited to announce the addition of Google's Gemini to our list of supported LLM providers, bringing the total number to 12.

New features, improvements, and fixes in Agenta.
We are excited to announce the addition of Google's Gemini to our list of supported LLM providers, bringing the total number to 12.
Bug Fixes
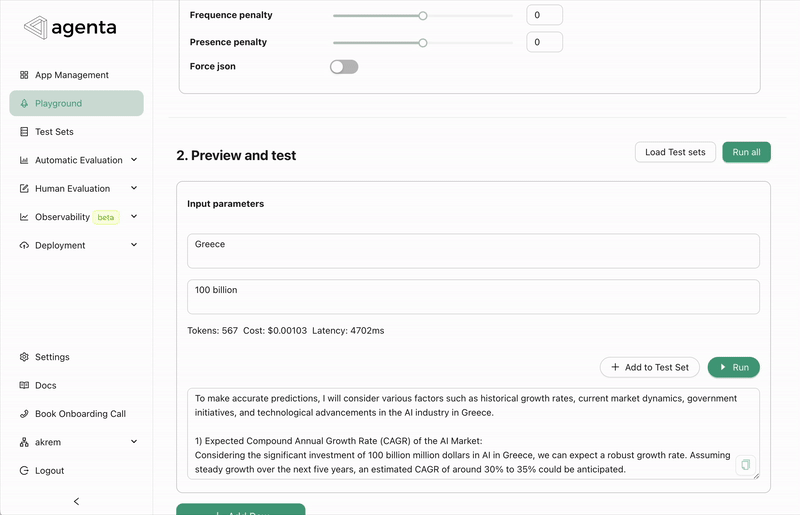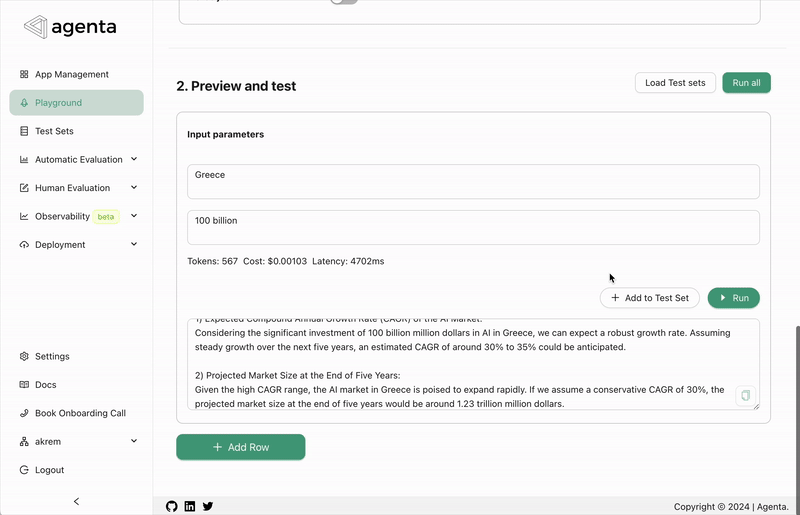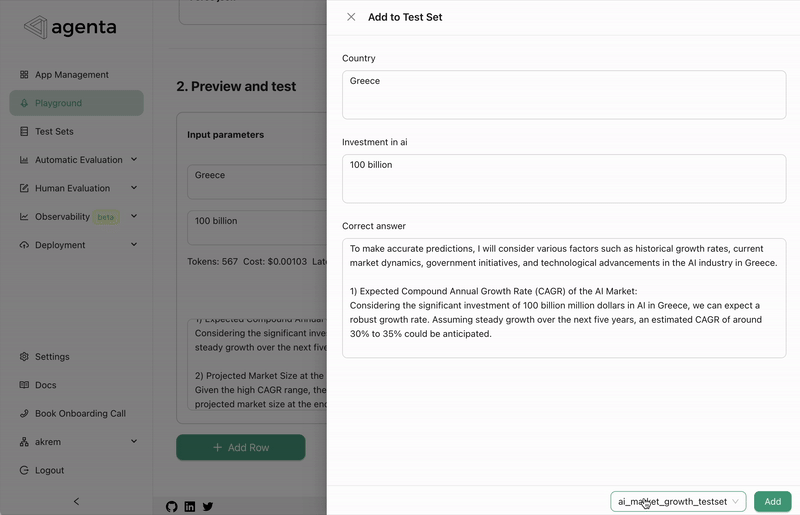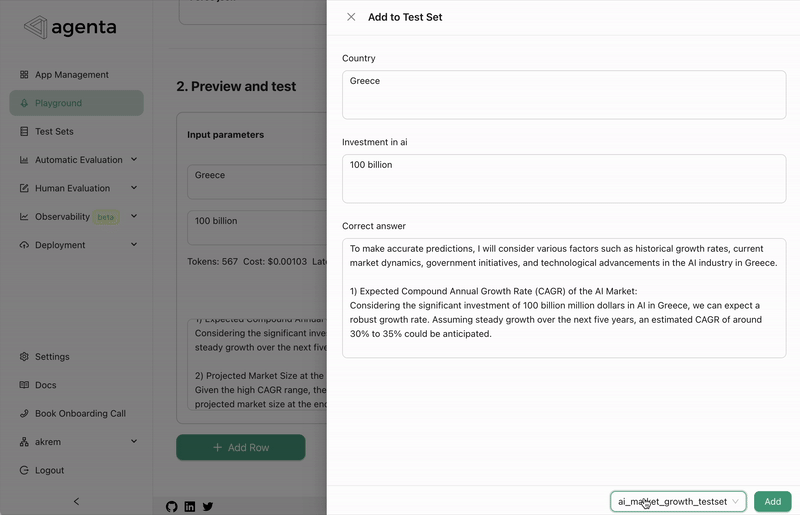
We've introduced a feature that allows you to use Agenta as a prompt registry or management system. In the deployment view, we now provide an endpoint to directly fetch the latest version of your prompt. Here is how it looks like:
from agenta import Agenta
agenta = Agenta()
config = agenta.get_config(base_id="xxxxx", environment="production", cache_timeout=200) # Fetches the configuration with caching
You can find additional documentation here.
Improvements


Bug Fixes
Bug Fixes
You can now monitor your application usage in production. We've added a new observability feature (currently in beta), which allows you to:
As of now, all new applications created will include observability by default. We are working towards a GA version in the next weeks, which will be scalable and better integrated with your applications. We will also be adding tutorials and documentation about it.


Find examples of LLM apps created from code with observability here.
You can now compare the latency and cost of different variants in the evaluation view.


Toggle variants in comparison view
You can now toggle the visibility of variants in the comparison view, allowing you to compare a multitude of variants side-by-side at the same time.


Improvements
Bug fixes
We have added some more evaluators, a new string matching and a Levenshtein distance evaluation.
Improvements
Bug fixes
Bug fixes